2018-06-25 01:52:01

alrighty, no clue if that's slow, average or wut but
```[2018-06-25 01:50:39] INFO snowblossom.miner.PoolMiner printStats 1-min: 5.760K/s, 5-min: 5.758K/s, hour: 693.236/s
[2018-06-25 01:50:39] INFO snowblossom.miner.PoolMiner printStats Shares: 1 (rejected 0) (blocks 0)
[2018-06-25 01:50:54] INFO snowblossom.miner.PoolMiner printStats 15 Second mining rate: 5752.999/sec - at this rate 12.151 minutes per share (diff 22.000)
[2018-06-25 01:50:54] INFO snowblossom.miner.PoolMiner printStats 1-min: 5.743K/s, 5-min: 5.762K/s, hour: 717.213/s
[2018-06-25 01:50:54] INFO snowblossom.miner.PoolMiner printStats Shares: 1 (rejected 0) (blocks 0)```
took me like 3 days to finally have it running (with the torrenting thingy, raid 0 setup and all xD)
Kayla
2018-06-25 02:34:14

no blocks all day at snowday today. ouch.
stoner19
2018-06-25 02:34:45
blocks are no longer cool
Fireduck
2018-06-25 02:36:36
is that due to the difficulty staying the same while nethash dropped by half (with the moving from field 6 to 7) ?
_idk how it works just yet, am still noob_ :stuck_out_tongue:
Kayla
2018-06-25 02:40:14
blocks are are and always will be cool
stoner19
2018-06-25 02:40:23
its probably because of miners jumping around from pool to pool.
stoner19
2018-06-25 04:09:49

Yeah, I noticed
Clueless
2018-06-25 04:10:00
I get like 10MH/s on snowday, then they leave for some reason
Clueless
2018-06-25 04:18:31
Ok, at this point I'd really like people to vote yes on prop 2.
Fireduck
2018-06-25 04:18:39
It gives school teachers a raise or something.
Fireduck
2018-06-25 04:19:27

I would agree to give teacher a raise if they get rid of that "untouchable after 10 years, bitches" rule
Ya_Mon
2018-06-25 04:20:32
better yet, fuck public schools, either private or homeschooling.
Ya_Mon
2018-06-25 04:31:14

I'm not so sure about prop 2... it essentially removes the hashrate requirement to advance snowfields.
Protovist
2018-06-25 04:32:38
@Protovist ? I don't think so.
Clueless
2018-06-25 04:33:40
Once someone is creating blocks with a higher snowfield, the weighting means that only blocks from that field will be added to the main chain.
Protovist
2018-06-25 04:34:28
Weight only comes from required field
Fireduck
2018-06-25 04:34:37
Not whatever someone mines with
Fireduck
2018-06-25 04:40:25
Someone can mine with field 11 and it makes no difference. Only the current active field matters for weight. Which continues to only be triggered by difficulty
Fireduck
2018-06-25 04:40:54
The work sum weighting had no effect on difficulty
Fireduck
2018-06-25 04:40:58

can difficulty drop?
complexring
2018-06-25 04:41:05
Yes
Fireduck
2018-06-25 04:41:15
But activated field can not
Fireduck
2018-06-25 04:41:22
awww
complexring
2018-06-25 04:41:25
ok
complexring
2018-06-25 04:41:27
got it
complexring
2018-06-25 04:42:30
snowday needs more power!
Clueless
2018-06-25 04:42:38
I'm givin it all she's got captain!
Clueless
2018-06-25 04:56:44
@Protovist I appreciate the scrutiny, but I think in this case there is nothing worry about. The fields activate with difficulty which adjusts based on hash rate. That all stays the same. The only difference is that once the chain activates a higher field, the chain with the higher field has an advantage in work sum weighting, which hopefully counter acts the hash rate drop when going to a higher field.
Fireduck
2018-06-25 04:57:15
That makes sense. As long as it's the activated field, my concern is void.
Protovist
2018-06-25 04:57:58
right. The weighting is based on activated field, not which field was used for a particular block.
Fireduck
2018-06-25 15:08:32

@Shoots did you try the amazon skylake xeons? at least the ones on digital ocean were rather performant, but i suspect there is less resource contention on DO than on AWS
Rotonen
2018-06-25 15:13:24

I have, but they only have 192gb of mem
Shoots
2018-06-25 15:13:31
and for some reason my miner uses 210gb
Shoots
2018-06-25 15:13:51
unless I run the latest version of the miner, then it maxes out the mem usage at 145gb, but the hr is much lower
Shoots
2018-06-25 15:14:11
and on top of that there's no available spots anymore
Shoots
2018-06-25 15:37:43
who is running Vauxhall? Would be nice to see miner list, pool hash, net hash, and time since last block on the website
stoner19
2018-06-25 15:38:37

agree
kaka
2018-06-25 15:45:36
@Shoots yeah, i suppose @Fireduck will eventually fix the miner to not require obscene amounts of JRE tweaking
Rotonen
2018-06-25 15:46:59
yeah tweaking the java parameters is beyond me
Shoots
2018-06-25 18:48:45
2% fee on protopool? Surprised there are that many miners for it
stoner19
2018-06-25 19:06:19
block density matters more early on
Rotonen
2018-06-25 19:53:54

INFO: Send new work to 13 workers. Keeping 10, Dropping 3
fydel
2018-06-25 19:54:07
what does the "Dropping" mean?
fydel
2018-06-25 19:54:54
i did have have it yesterday. but now i have 1-5 dropping in nearly every message.
fydel
2018-06-25 19:55:22
network issue?
fydel
2018-06-25 19:56:02
look at the code, probably something like ’did not hear back from it in a while’
Rotonen
2018-06-25 19:58:48
drop_count++;
//logger.info("Error in send work: " + t);
fydel
2018-06-25 20:00:15
rejected shares?
fydel
2018-06-25 20:03:00
INFO: Work block load error: java.lang.RuntimeException: Unable to select a field of at least 7
fydel
2018-06-25 20:03:12
ah. damn. i think my snowfield is broken.
fydel
2018-06-25 20:16:54
curious, so definitely not just an old field?
Rotonen
2018-06-25 20:23:04
no. after closer inspection it was a wrong sym link.
fydel
2018-06-25 20:39:49
if I create a swap file in ubuntu will the miner use that without enabling hybrid mining?
Shoots
2018-06-25 20:39:51
drop_count about clients that are removed due to the links already being broken
Fireduck
2018-06-25 20:40:00
noted by trying to send them work resulting in errors
Fireduck
2018-06-25 20:40:10
so it means they have disconnected and are gone
Fireduck
2018-06-25 20:40:22
but grpc doesn't really tell us that until we try to send something
Fireduck
2018-06-25 21:07:11
@Shoots see vm.swappiness
Rotonen
2018-06-25 21:35:32
swap file seems to lock up the vm
Shoots
2018-06-25 21:48:35
try zram instead:
https://www.kernel.org/doc/Documentation/blockdev/zram.txt
Rotonen
2018-06-25 21:55:22
im trying hybrid mining now
Shoots
2018-06-25 21:55:50
I really want to get this m5d instance running, it has the highest hash per $, but has a tad too little of memory
Shoots
2018-06-25 21:56:04
how much does it have?
Fireduck
2018-06-25 21:56:09
192
Shoots
2018-06-25 21:56:18
my miner seem to use about 210gb
Shoots
2018-06-25 21:56:22
strange
Fireduck
2018-06-25 21:56:50
when I installed java 10 and the newest miner last night it was using only 145gb
Shoots
2018-06-25 21:56:59
but something wasnt right cause the hr was way too low
Shoots
2018-06-25 21:57:58
now Ive compiled from source with openjdk and trying hybrid mining with 180gb set as my cache size
Shoots
2018-06-25 22:01:35
@Shoots if you're like 10G short, try allocating 50G to zram
Rotonen
2018-06-25 22:04:10
@Shoots debian 9, default-jre-8-headless, and i'm getting by 135G ram use for memfield (though bumped -Xmx to 200G as why not, rather have it fire the GC less often)
Rotonen
2018-06-25 22:04:57
@Shoots in a nutshell zram is a way of trading spare cpu cycles for 'more ram' - even with ram mining snowblossom is not actually cpu limited
Rotonen
2018-06-25 22:09:38
I wonder if the number of cores or threads impacts the ram usage?
Shoots
2018-06-25 22:11:25
it does
Rotonen
2018-06-25 22:12:06
try to find the minimal thread count where the next one over does not bring you any meaningful extra
Rotonen
2018-06-25 22:12:44
Oh ok
Shoots
2018-06-25 22:12:54
Its a 48c VM I have it set to 96
Shoots
2018-06-25 22:12:57
start with 1, check where the ram use is after 1min and 5min are ~equal, double, repeat until gain is ~naught
Rotonen
2018-06-25 22:13:22
those are vcores so 48 or 24 more plausible sane thread counts
Rotonen

2018-06-25 22:13:28
Getting 0h with hybrid miner
Shoots
2018-06-25 22:13:44
you have 48 potentially-shared-with-other-guests hyperthreads from the hypervisor
Rotonen
2018-06-25 22:13:57
Yeah
Shoots
2018-06-25 22:14:23
but try memfield and 12, 24, 48
Rotonen
2018-06-25 22:14:33
start with 12, to see if you get it going at all
Rotonen
2018-06-25 22:15:06
usually in high performance computing contexts `cloud vcore count / 4` ~ `real cpu count equivalent`
Rotonen
2018-06-25 22:16:12
why am I not hashing I wonder
Shoots
2018-06-25 22:16:16
but borderline impossible to guess how the memory channels are provisioned for amazon guests, if they do certain things not optimally your snowblossom performance can actually be up to dumb luck in how it just happened to map when provisioned (or even based on hypervisor load)
Rotonen
2018-06-25 22:16:24
well that's just a miner bug, i'd say
Rotonen
2018-06-25 22:16:36
yeah nothing to worry about lol
Shoots
2018-06-25 22:16:52
it seemed to cap out at 138gb or ram usage
Shoots
2018-06-25 22:16:54
but 0h
Shoots
2018-06-25 22:17:16
with what exact config?
Rotonen
2018-06-25 22:17:37
# network
# (snowblososm/mainnet, teapot/testnet, spoon/regtest)
network=snowblossom
#node_host=
pool_host=http://snow.protopool.io
#node_port=23380
#pool_host=http://pool.snowblossom.cluelessperson.com
# the location of "snow" fields for mining
snow_path=snow/mainnet
# automatically generate mining snow files.
# CAUTION! INTENSIVE! You may wish to torrent instead.
# torrents: https://snowblossom.org/snowfields/index.html
#auto_snow=true
# pick an address (at random for now)from this wallet to mine to
#mine_to_wallet=wallets/mainnet
# or mine to address
mine_to_address=snow:
# number of cpu threads to commit to PoW
threads=96
memfield=true
memfield_precache_gb=180
Shoots
2018-06-25 22:17:56
i'm running fine with
```
memfield=true
mine_to_address=<redacted>
network=snowblossom
pool_host=http://snowplough.kekku.li
snow_path=snow/mainnet
threads=24
```
Rotonen
2018-06-25 22:18:02
~135Gb ram use
Rotonen
2018-06-25 22:18:11
6 core E5
Rotonen
2018-06-25 22:18:17
whats your hr with 24 threads?
Shoots
2018-06-25 22:18:30
850k, which is what i'm expecting as well
Rotonen
2018-06-25 22:18:48
thats low compared to what I get though, with 24 threads I get about 1.2mh
Shoots
2018-06-25 22:18:58
24cores I should say
Shoots
2018-06-25 22:19:01
i had a script iterate from 1 to 128 threads and 24 was the sweet spot
Rotonen
2018-06-25 22:19:28
```
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-1650 v3 @ 3.50GHz
Stepping: 2
CPU MHz: 3599.975
CPU max MHz: 3800,0000
CPU min MHz: 1200,0000
BogoMIPS: 6983.10
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0-11
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb invpcid_single kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts
```
older hardware, in line with what i expect
Rotonen
2018-06-25 22:20:15
oh its 12 cores, thats pretty good actually for 12 cores
Shoots
2018-06-25 22:20:22
thats your own hardware?
Shoots
2018-06-25 22:20:22
6 cores
Rotonen
2018-06-25 22:20:25
oh
Shoots
2018-06-25 22:20:33
well thats really good for 6 cores damn
Shoots
2018-06-25 22:20:52
it's not the cores, it's not the memory channels, it's the ratio of cores to memory channels
Rotonen
2018-06-25 22:20:57
i have 6 cores over 4 memory channels
Rotonen
2018-06-25 22:21:23
then the generational gains are like 5% per generation for the processor cores and about 3% for memory
Rotonen
2018-06-25 22:21:40
so i could get 1M on a modern xeon and something like 2,5M on an AMD EPYC
Rotonen
2018-06-25 22:22:00
potentially 1,6M on the new i9-esque 6 channel stuff
Rotonen
2018-06-25 22:22:24
so if you find an old intel E7 for cheap, give that a spin, that should always land you north of 1M
Rotonen
2018-06-25 22:23:17
but those processors usually cost tens of thousands when new, so they're probably going to be used to the bitter end by whomever needs to buy them (and they're actually usually bought more for the reliability than the throughput)
Rotonen
2018-06-25 22:24:03
https://ark.intel.com/products/82765/Intel-Xeon-Processor-E5-1650-v3-15M-Cache-3_50-GHz Intel® Xeon® Processor E5-1650 v3 (15M Cache, 3.50 GHz) quick reference guide including specifications, features, pricing, compatibility, design documentation, ordering codes, spec codes and more.
Rotonen
2018-06-25 22:24:19
and this processor is from 2014
Rotonen
2018-06-25 22:24:36
old hardware is rather viable
Rotonen
2018-06-25 22:26:40
@Shoots but i'm curious as to what you get with 12 threads and memfield
Rotonen
2018-06-25 22:27:00
@Shoots that's what i'd start with given the vcores / 4 shorthand rule
Rotonen
2018-06-25 22:28:53
what do you mean by shorthand rule?
Shoots
2018-06-25 22:29:00
just by using 12 threads?
Shoots
2018-06-25 22:29:28
no, if you use any cloud services for anything performance critical and you compare to real hardware, dividing the cloud 'core count' by four makes it more apples to apples in what one can expect
Rotonen
2018-06-25 22:30:04
well Im getting 3.4mh with 96 threads right before it runs out of mem
Shoots
2018-06-25 22:30:47
that means the backing system is a multi socket system and you're getting really lucky in how the memory of your VM is spread over 12 channels (or 24 channels if it is a quad socket system)
Rotonen
2018-06-25 22:31:13
its probably cause its latest gen
Shoots
2018-06-25 22:31:33
probably dual socket and mostly memory bandwidth idle by your neighbours, if i estimate about 300kH/s per memory channel, that's 3,6M
Rotonen
2018-06-25 22:32:05
usually the truth about hashes per memory channel maximums is somewhere between 200kH/s and 400kH/s
Rotonen
2018-06-25 22:32:29
in my 'wizard' page i'm lowballing that to 200, but i really need to format that whole thing better
Rotonen
2018-06-25 22:32:37
I wonder if it will use more memory cause Im running in tmux sesssion
Shoots
2018-06-25 22:32:42
no
Rotonen
2018-06-25 22:33:45
ok cause I was using damn near 130gb with field 6
Shoots
2018-06-25 22:33:54
trying 12 threads now
Shoots
2018-06-25 22:34:11
@Shoots I could write a script that experiments with different values and charts out the most efficient settings
Clueless
2018-06-25 22:34:27
@Clueless rather make the miner autotune the thread count at runtime
Rotonen
2018-06-25 22:34:59
it would be nice if it was a separate utility or if it asked you if you wanted to run it the first time
Shoots
2018-06-25 22:35:04
i'll actually take a stab at that next week most likely, i've not touched java since 1.4 EE was the hot new thing just out
Rotonen
2018-06-25 22:35:23
@Shoots i'd rather it always warms up the system carefully and speeds up slow
Rotonen
2018-06-25 22:35:42
@Shoots not starting from 1 thread, but from a sensible ballpark, like the system thread count
Rotonen
2018-06-25 22:35:54
or quarter that and then doubling until matching and then trying +50% or somesuch
Rotonen
2018-06-25 22:36:04
if i actually bother, can figure it out as i go
Rotonen
2018-06-25 22:37:24
the most naive approach is of course to just let it bump the thead count up one at a time, but that'll take a very long time to get hot on large systems
Rotonen
2018-06-25 22:37:31
like 3 hours or so
Rotonen
2018-06-25 22:38:05
miners don't even seem to have patience for the torrenting of a snow field, memfield loading or getting the first stable 5min rate :slightly_smiling_face:
Rotonen
2018-06-25 22:38:44
it would need to use a lower field to do it faster
Shoots
2018-06-25 22:39:36
i dream of the fields being split into 1G files which can be shoved into ram on demand until hitting the heap limit (and a script which sets the heap limit upon launch to be a bit shy of the available ram)
Rotonen
2018-06-25 22:39:50
is there anyway I can see whats in ram and see whats eating up the extra 90gb overtop of the field?
Shoots
2018-06-25 22:40:08
see ptrace, strace
Rotonen
2018-06-25 22:41:53
strace -p 2031
strace: Process 2031 attached
futex(0x7f40126309d0, FUTEX_WAIT, 2033, NULL
Shoots
2018-06-25 22:43:22
seems there is a java specific one:
https://docs.oracle.com/javase/7/docs/technotes/tools/share/jmap.html
that should feed into any vm visualizers
Rotonen
2018-06-25 22:43:49
https://visualvm.github.io/ <- like this
Rotonen
2018-06-25 22:48:26
dumping now
Shoots
2018-06-25 22:48:31
from a different vm
Shoots
2018-06-25 22:48:37
12 threads already up to 150gb
Shoots
2018-06-25 22:50:37
```
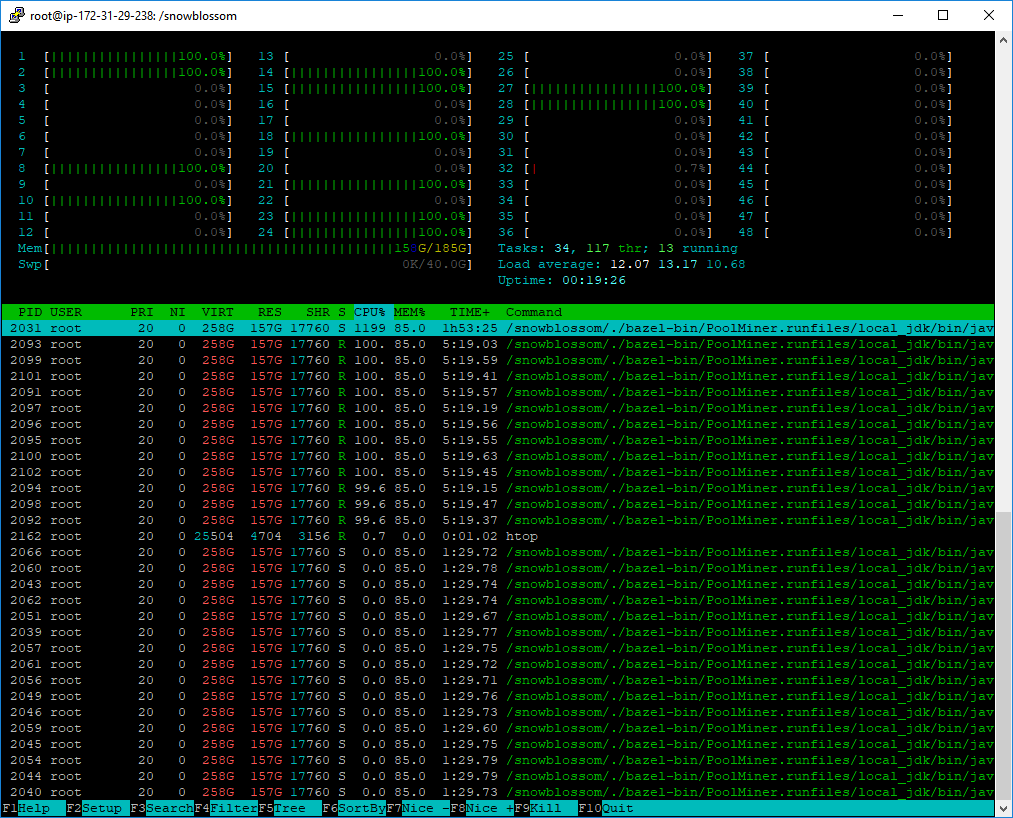
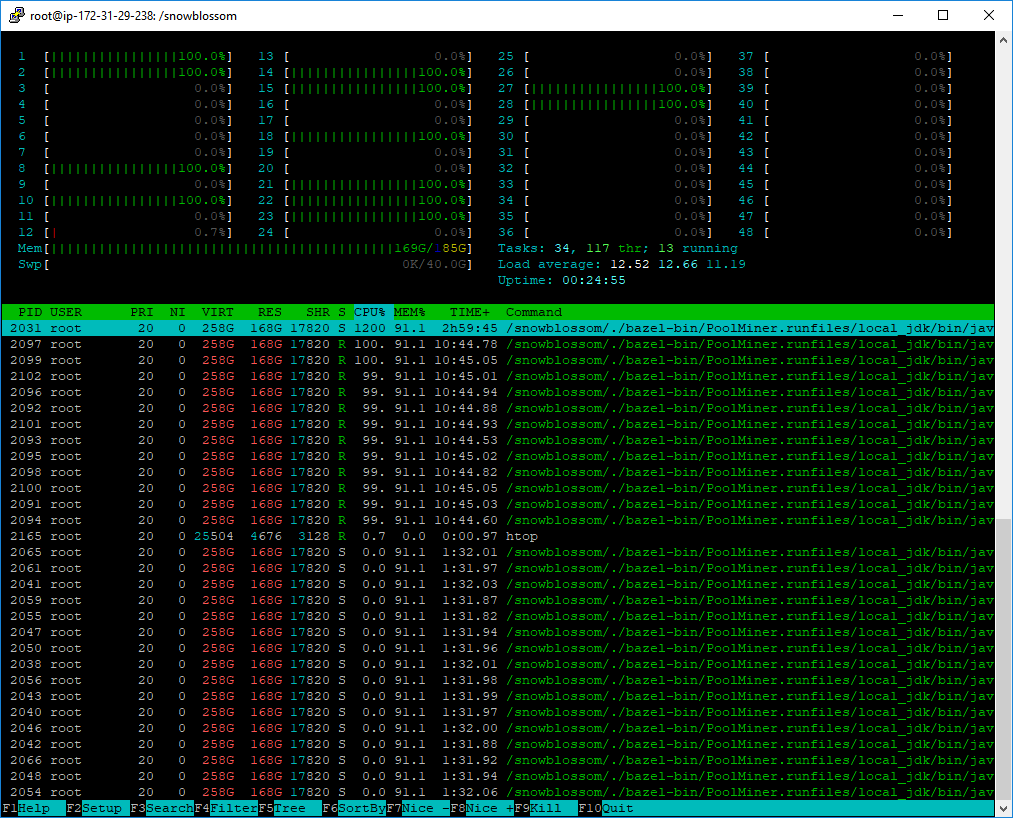
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7380 root 35 15 0,206t 0,136t 17820 S 1180 55,5 27:04.99 java -XX:+UseParallelOldGC -Xmx200G -jar PoolMiner_deploy.jar miner.conf
```
Rotonen
2018-06-25 22:51:11
what number do you track? RES is the one which matters
Rotonen
2018-06-25 22:51:30
Shoots
2018-06-25 22:51:40
im going to try your command
Shoots
2018-06-25 22:52:04
the parallel old gc, when used alone, decreases performance
Rotonen
2018-06-25 22:52:10
that's just the random test run i'm on currently
Rotonen
2018-06-25 22:52:16
but skip that one
Rotonen
2018-06-25 22:52:30
(or maybe, since you have a different java, try it? dunno at this point)
Rotonen
2018-06-25 22:52:42
Im running openjkd8
Shoots
2018-06-25 22:52:50
cause thats what I needed to build from source
Shoots
2018-06-25 22:53:02
i build on a mac
Rotonen
2018-06-25 22:54:21
but on debian 9, the package `default-jre-headless` works the best for me
Rotonen
2018-06-25 22:54:36
and the best i get with that so far is `nice -n 15 java -Xmx200G -jar PoolMiner_deploy.jar miner.conf`
Rotonen
2018-06-25 22:55:03
then oracle linux with oracle java can get me more, but requires tens of parametres for the jre for ultimately very little gain
Rotonen
2018-06-25 22:56:20
theres gotta be something I can do to reduce this memory issue
Shoots
2018-06-25 22:56:21
could also be nicing the miner perversely enough gives one slight extra oompf as it gets less in the way of system things
Rotonen
2018-06-25 22:56:33
any chance you could compress your dir for me?
Shoots
2018-06-25 22:56:37
and share
Shoots
2018-06-25 22:56:59
Shoots
2018-06-25 22:57:15
now, this is getting into dangerous country as i could just give you any malware
Rotonen
2018-06-25 22:57:23
I trust you
Shoots
2018-06-25 22:58:06
i'm half sure it's something to do with the fact we use a different jre, though
Rotonen
2018-06-25 22:58:17
bazel should output the same `_deploy.jar`
Rotonen
2018-06-25 22:58:40
I tried building with java 10 and got an error
Shoots
2018-06-25 22:58:56
uninstalled java 10 and installed openjkd and it worked fine
Shoots
2018-06-25 22:59:21
also weird that when hybrid mining I get 0h/s
Shoots
2018-06-25 22:59:28
https://packages.debian.org/default-jre-headless <- the default on stretch is 8
Rotonen
2018-06-25 22:59:31
Does it show 0 until you are fully done loading?
Shoots
2018-06-25 22:59:36
no, it does not
Rotonen
2018-06-25 23:00:41
hmm, or at least not when memfielding, don't recall about hybrid, can try
Rotonen
2018-06-25 23:00:44
mem dump to a text file used up my disk space and ran out :S
Shoots
2018-06-25 23:01:05
well, it is an actual mem dump, that's the full memory content
Rotonen
2018-06-25 23:01:23
yeah woops, just wanted to print out what was in it
Shoots
2018-06-25 23:01:48
the size of things is a bit nontrivial, yeah
Rotonen
2018-06-25 23:03:04
@Shoots actually try memfield with `-Xmx180G -Xms180G`
Rotonen
2018-06-25 23:03:22
gets out of memory error
Shoots
2018-06-25 23:03:36
tried that last night
Shoots
2018-06-25 23:04:00
what's using the memory before you start java? if you have 192, that should still leave 12 free
Rotonen
2018-06-25 23:04:17
and as said, try that with threads=1
Rotonen
2018-06-25 23:04:21
to see if that starts
Rotonen
2018-06-25 23:05:20
it shows up as 185gb
Shoots
2018-06-25 23:05:56
if I dont set xmx higher than java uses I get out of mem error
Shoots
2018-06-25 23:06:48
which field do you try to mine with?
Rotonen
2018-06-25 23:06:57
7 should fit
Rotonen
2018-06-25 23:07:09
8 would not
Rotonen
2018-06-25 23:07:19
7
Shoots
2018-06-25 23:07:41
try with the old gc from above and both xmx and xms and threads 1
Rotonen
2018-06-25 23:07:57
it almost sounds like your memfielding is double
Rotonen
2018-06-25 23:09:09
also the threads 1 will give me a more exact figure on where the per channel bandwidth lands on those systems
Rotonen
2018-06-25 23:10:19
for ram ballparks when 1min and 5min agree close enough that's a result
Rotonen
2018-06-25 23:17:50
plotted numbers and i pay one eurocent per hour per kilohash on my infra for mining
Rotonen
2018-06-25 23:19:28
no, that's actually not right at all
Rotonen
2018-06-25 23:19:34
yeah, time to sleep :smile:
Rotonen
2018-06-25 23:19:47
(failing way too hard at excel references)
Rotonen
2018-06-25 23:24:17
hmmm I had a partial field 8 in my snow/mainnet folder from one time I accidentally had autosnow enabled, I wonder if thats what was causing my issue
Shoots
2018-06-25 23:24:57
when I would launch the miner I noticed it says building field 8, but then never continues to build it.
Shoots
2018-06-25 23:25:08
cause I have autosnow disabled now
Shoots
2018-06-25 23:27:23
that could explain the 0 hash
Rotonen
2018-06-25 23:27:52
@Shoots actually drop the memfield parametre, drop the xmx, just let it read from the disk and let fscache slowly take over
Rotonen
2018-06-25 23:28:28
Don't forget to fprot the tarball
Fireduck
2018-06-25 23:32:15
Is fscache automatic or do I have to enable it?
Shoots
2018-06-25 23:35:39
also if I still have snowfield 6 will it try to load that into mem?
Shoots