2018-06-25 00:58:00

hey, so i got 2x 128 Gb SSDs in RAID 0, finished torrenting the 128 Gb field 7, got it into the folder, added the pool into config/pool-miner.conf
basically, those are uncommented
```network=snowblossom
log_config_file=configs/logging.properties
pool_host=pool_host=http://snow.vauxhall.io
snow_path=snow
mine_to_address=<address>
threads=8```
_sidenote: miner.sh is working having the average speed with time to find a block_
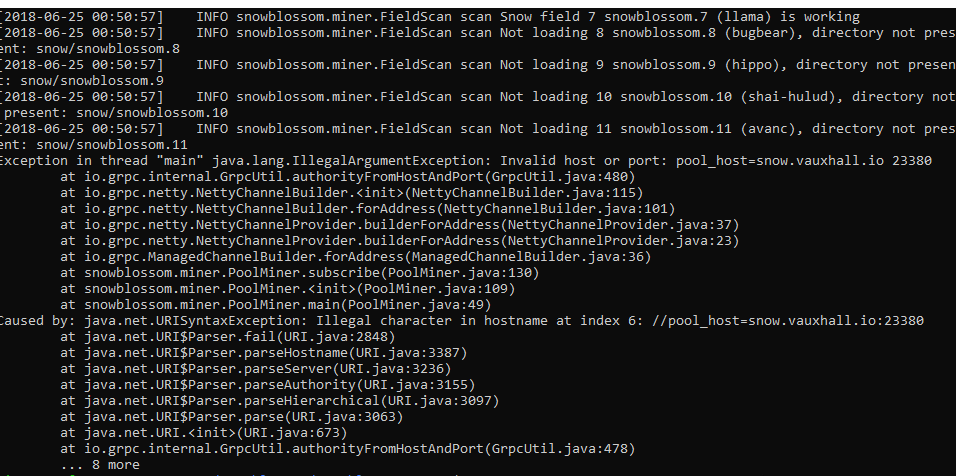
but when running ./pool-miner.sh i get an error, did i miss something ? like a port or something else ?
Kayla
2018-06-25 00:59:42
i mean, i tried protopool first but it was the same
Kayla
2018-06-25 01:00:22

are you running node while trying to mine?
complexring
2018-06-25 01:00:32
also maybe in <#CB4CYRTPG|mining> too
complexring
2018-06-25 01:01:01
yeah running the node, else miner.sh probably wouldn't work either (which, is working fine)
Kayla
2018-06-25 01:01:34

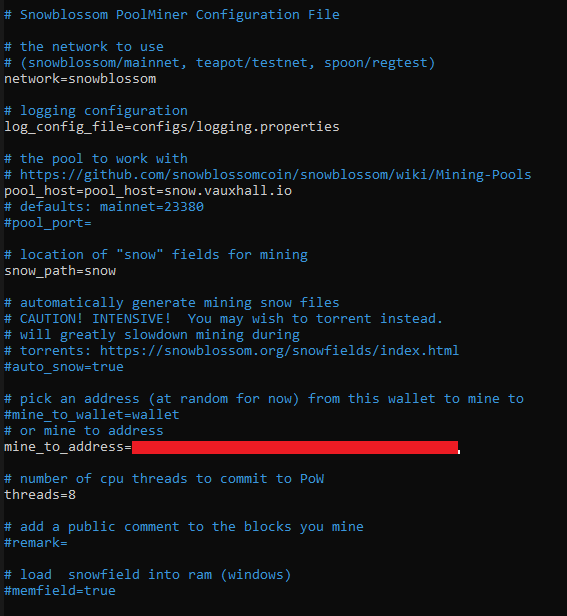
do you have a comment starting with //? replace with "#"
dystophia
2018-06-25 01:03:52
pool_host=pool_host=...
dystophia
2018-06-25 01:04:05
once is enough
dystophia
2018-06-25 01:04:06
oh
Kayla
2018-06-25 01:04:07
thanks
Kayla
2018-06-25 01:04:09
^^'
Kayla
2018-06-25 01:04:46
yeah, seems to work now, haha, i can be really dumb sometimes UwU
Kayla
2018-06-25 01:04:53
ty :heart:
Kayla
2018-06-25 01:05:34
you´re welcome
dystophia
2018-06-25 01:45:55

doot
Clueless
2018-06-25 02:52:27

Can anyone tell me if there's a specific version of Java that uses less memory on Ubuntu?
Shoots
2018-06-25 02:53:26
Also do the newer version of the miner require less mem? I have xmx set to 192 and it's running out
Shoots
192 mb or gb?

2018-06-25 02:58:36
Gb
Shoots
-Xmx192g
thats what you've got
and you can run free -m or htop and actually see 192 gigs of memory being used up?
My immediate guess is perhaps you forgot the 'g'
I can run this thing with -Xmx140g using standard openjdk available on ubuntu
2018-06-25 03:05:32
definitely have the g
Shoots
2018-06-25 03:05:46
Im using an old original version of the miner, going to try the altest
Shoots
2018-06-25 03:05:49
latest*
Shoots
2018-06-25 03:21:19
yeah for some reason these aws instances require you set the xmx setting much higher than 140g like yourself
Shoots
2018-06-25 05:19:14
breaking the hell out of the explorer for a minute
Fireduck
2018-06-25 05:23:15
once it resyncs we will have history on addresses
Fireduck
is explorer code open source
2018-06-25 05:28:42
yep
Fireduck
2018-06-25 05:28:49
in main repo, called shackleton
Fireduck
shackleton ?
yea ok
2018-06-25 05:28:54
because it is a snow explorer
Fireduck
ahh
2018-06-25 05:30:37
well the old version of the miner is much faster Ive determined. 48c vm gets 3.4mh on old version and 2.1 on new version. Memory usage seems to cap out at 145gb on new version where old version will use over 200gb
Shoots
2018-06-25 05:32:18
very strange
Fireduck
2018-06-25 05:33:29
explorer now supports searching by block number
Fireduck
2018-06-25 05:34:00
I wonder if the memory fix for windows caused an issue with memory usage in linux?
Shoots
2018-06-25 05:34:00
and shows history for addresses: https://explorer.snowblossom.org/?search=snow%3Ahykhya7x6mthn8whz4ga997m26p3jgykx6qa2zr7
Fireduck
2018-06-25 05:34:20
@Shoots certainly possible
Fireduck
2018-06-25 05:34:38
the problem with something like the miner is optimization on top of optimization soon gets very strange
Fireduck
2018-06-25 05:35:02
If you write up your findings with as much detail as you can in a github issue we can take a look
Fireduck
2018-06-25 05:35:03
are there any new settings I can try to configure?
Shoots
2018-06-25 05:36:13
in mining tuning wiki page
Fireduck
2018-06-25 05:40:21
im wondering if theres some configs on by default that arent in the readme
Shoots
2018-06-25 06:27:56

@Shoots which GC do you use for old and new heap objects, and with which parametres
Rotonen
2018-06-25 12:24:25
Ive tried java 8 and java 10, java 10 using G1. doesnt make a difference. The old miner just uses more memory and gets higher hashrate
Shoots
2018-06-25 12:24:50
now to determine which version of the miner caused the issue
Shoots
2018-06-25 12:35:34
@Shoots no, you can tweak which implementation is used for old objects on the heap and which for new objects and then still the parametres of the chosen implementations
Rotonen
2018-06-25 12:36:17
@Shoots there’s an asymmetry of expected object lifetimes as far as i’ve observed
Rotonen
2018-06-25 12:37:11
@Shoots also can adjust what constitutes old
Rotonen
2018-06-25 12:38:19
Im not sure how to do that, can you help?
Shoots
2018-06-25 13:22:36
read the jre docs
Rotonen
2018-06-25 13:32:09
What's the flag for hybrid mining? I don't see it in the miner config
Shoots
2018-06-25 13:36:14

https://snowplough.kekku.li/wizard/howto/ A quickstart wizard to help you get started with mining Snowblossom.
AlexCrow
2018-06-25 13:49:54
@Shoots https://snowblossom.slack.com/archives/CAS0CNA3U/p1529854212000136 ```
double precacheGig = config.getDoubleWithDefault("memfield_precache_gb", 0);
```
Rotonen
2018-06-25 13:50:13
Thanks guys
Shoots
2018-06-25 14:48:48

Do you have a 1000000/sec for each computer?
Ninja
2018-06-25 15:06:54
1M .. 2M is the expected expected ballpark for RAM on quad channel and up systems, 3M with EPYC, and up to 5M on prohibitively expensive enterprise hardware
Rotonen
2018-06-25 17:11:39
I am outsourcing my mining. Spending too much time screwing with moving hardware around when I should be programming.
Fireduck
2018-06-25 17:12:04
By which I mean I am shoving hardware at @Clueless
Fireduck
2018-06-25 17:26:56
INFO: Generating snow field at 4262.25 writes per second. Estimated total runtime is 244.92 hours. 0.23 complete.
Fireduck
2018-06-25 17:27:02
good old field 11.
Fireduck
2018-06-25 17:27:12
We shall see if I lose power again before it finishes.
Fireduck
2018-06-25 17:27:22

is there no checkpointint?
Tyler Boone
2018-06-25 17:27:54
no, a checkpoint would involve a complete copy of the working snowfield
Fireduck
2018-06-25 17:27:59
so in this case be 2tb
Fireduck
2018-06-25 17:28:07
plus the state of the various prngs
Fireduck
2018-06-25 17:28:20
plus if I screw it up everyone will laugh at me
Fireduck
2018-06-25 17:28:59
got half way done last time and someone from the power company came and pulled out my meter
Fireduck
2018-06-25 17:29:22
you could have built the algorithm in a way that enabled checkpointing
Tyler Boone
2018-06-25 17:30:16
for example by making idempotent sections which write values into some set of areas and don't read any from that same set
Tyler Boone
2018-06-25 17:31:12
the entire point of the algorithm was to make checkpointing very hard
Fireduck
2018-06-25 17:31:24
different kind of checkpoint
Tyler Boone
2018-06-25 17:31:48
not very different
Fireduck
2018-06-25 17:31:53
totally different
Tyler Boone
2018-06-25 17:31:57
you aren't understanding me
Tyler Boone
2018-06-25 17:32:21
lets say you want to create a checkpoint every 10,000 writes.
Tyler Boone
2018-06-25 17:32:48
have it such that those 10,000 writes don't read from any of the areas those 10,000 writes are going to
Tyler Boone
2018-06-25 17:33:01
it still reads from the rest of the snowfield
Tyler Boone
2018-06-25 17:33:13
so you need the entire snowfield up to that point
Tyler Boone
2018-06-25 17:33:38
so yeah, you could "checkpoint", but the checkpoint requires data the size of the entire snowfield
Tyler Boone
2018-06-25 17:33:56
obviously the first pass would have no checkpoint
Tyler Boone
2018-06-25 17:34:15
wouldn't the checkpoint be the size of the entire file (which I can do now)?
Fireduck
2018-06-25 17:34:22
yes, exactly
Tyler Boone
2018-06-25 17:34:47
I can checkpoint it now, if I want to store a complete copy of the file and all the rng state
Fireduck
2018-06-25 17:34:50
I thought you just said if you lose power you have to start over.
Tyler Boone
2018-06-25 17:34:58
yes, I do
Fireduck
2018-06-25 17:35:02
well, there you go.
Tyler Boone
2018-06-25 17:35:10
I mean I could implementing checkpointing without change the algorithm
Fireduck
2018-06-25 17:35:19
sweet
Tyler Boone
2018-06-25 17:35:24
I won't
Fireduck
2018-06-25 17:35:27
but I could
Fireduck
2018-06-25 17:35:37
I'm not convinced that you can
Tyler Boone
2018-06-25 17:35:44
I love you too
Fireduck
2018-06-25 17:35:55
BURN
Tyler Boone
2018-06-25 17:35:57
heh
Fireduck
2018-06-25 17:36:21
the point when it brings all the threads together for the lock step synchronization would make a natural checkpointing spot
Fireduck
2018-06-25 17:36:36
what if some writes happen to the snowfield after you save the rng state?
Tyler Boone
2018-06-25 17:36:55
is it guaranteed that starting from that last lock-step would not read any of those written values?
Tyler Boone
2018-06-25 17:37:23
for example, if you read a value before overwriting it, you are most likely screwed.
Tyler Boone
2018-06-25 17:37:24
I would have to stop all execution, save file and rng state and then resume
Fireduck
2018-06-25 17:37:35
At the point I have the synchronization lock all writes are stopped
Fireduck
2018-06-25 17:38:03
we'll have to go over this in person I think
Tyler Boone
2018-06-25 17:39:21
probably
Fireduck
2018-06-25 17:40:09
ACID, snow - oh my
Rotonen
2018-06-25 17:40:32
https://github.com/snowblossomcoin/snowblossom/blob/master/lib/src/SnowFall.java#L191 - at that point all writers are not doing anything ```
syncsem.acquire(MULTIPLICITY);
```
Fireduck
2018-06-25 17:40:44
and the thread running that line is the only thing going anything
Fireduck
2018-06-25 17:40:51
I mean after that returns
Fireduck
2018-06-25 17:42:48

anywhere to see nethash?
stoner19
2018-06-25 17:52:45
it is an estimate anyways
Fireduck
2018-06-25 17:52:47
hard to be sure
Fireduck
2018-06-25 17:56:16
@Tyler Boone and to answer your question, there is a check within each step to make sure a page is only touched once in each step
Fireduck
2018-06-25 17:56:54
for it to be checkpointable, the written pages in a step cannot be read in the same step
Tyler Boone
2018-06-25 17:57:13
when a page is involved in a step, it is read and written in the step
Fireduck
2018-06-25 17:57:26
then your screwed
Tyler Boone
2018-06-25 17:57:31
you are drunk
Fireduck
2018-06-25 17:57:38
you're even
Tyler Boone
2018-06-25 17:57:49
any process can be checkpointed
Fireduck
2018-06-25 17:58:50
you stop doing things, save the state somewhere and resume doing things
Fireduck
2018-06-25 17:59:10
yes, but we want to discuss checkpoints which don't massively slowdown processing
Tyler Boone
2018-06-25 17:59:19
oh, without massive slowdowns
Fireduck
2018-06-25 17:59:30
that is a different weasel
Fireduck
2018-06-25 17:59:43
could actually do it with zfs or btrfs snapshots
Fireduck
2018-06-25 17:59:45
every n something
Rotonen
2018-06-25 18:27:09
anyone know what this is about? https://pastebin.com/XpG1Zbzt
stoner19
2018-06-25 18:28:30
nevermind. install process just doesn't make `/logs/` dir by default
stoner19
2018-06-25 18:36:17
`//Limited to 100 bytes, so short letters to grandma` nice one @Fireduck :slightly_smiling_face:
stoner19
2018-06-25 18:39:37
maybe mkdir logs?
Fireduck
2018-06-25 18:43:33
@Fireduck yes I did that. Thanks. As I said, the build process just doesn't build the logs directory so I had to do that manually.
stoner19
2018-06-25 18:44:53
which install process did you use?
Fireduck
2018-06-25 18:45:35
I did
```
git clone https://github.com/snowblossomcoin/snowblossom.git
cd snowblossom/
bazel build :all
```
stoner19
2018-06-25 18:48:57
ok
Fireduck
2018-06-25 18:50:02
would you like me to open an issue on github for this? so that the code can be fixed to create the `/logs/` dir?
stoner19
2018-06-25 18:51:05
go for it
Tyler Boone
2018-06-25 18:51:12
will do so shortly.
stoner19
2018-06-25 18:51:18
thanks
Tyler Boone
2018-06-25 18:57:06
GCE nvme is terrible
Fireduck
2018-06-25 18:57:10
like 10kh/s
Fireduck
2018-06-25 18:57:18
Anyone tries the AWS nvme?
Fireduck
2018-06-25 18:57:56
get more hash rate from a taco
Fireduck
2018-06-25 19:05:48
md5 instance might be alright, but there's no spot instances available
Shoots
2018-06-25 19:07:46
just be careful not to store the snowfield on an ebs volume - they charge you per io-operation
dystophia
2018-06-25 19:07:47
@Fireduck all cloud ’ssd’ or ’nvme’ are gonna suck, they just use those as a shorthand for ’gen + 1 SAN’
Rotonen
2018-06-25 19:08:45
@Shoots there are if you contact sales and commit to a flexible fleet of 10 .. 100 for a year, but... :D
Rotonen
@dystophia lots of instance types have EBS-only disks
2018-06-25 19:24:57
Just don´t mine directly from an EBS volume
dystophia
but loading snowfield from EBS into RAM is not too expensive right
2018-06-25 19:25:37
right
dystophia
2018-06-25 19:26:12
mining directly from it is slow anyway, just helping others avoid this mistake
dystophia
2018-06-25 19:46:58

thanks
fydel
2018-06-25 21:05:30
talked to an engineer at google. It is working as intended, when you provision ssd (local or network) you are given an IOPS budget
Fireduck
2018-06-25 21:05:39
and it gets that budget pretty well
Fireduck
2018-06-25 21:05:42
but it isn't amazing
Fireduck
2018-06-25 21:18:55
@Fireduck as said, the ’nvme’ there is a marketing stamp on sustained 4k read iops - i suppose the next one they’ll call 3d nand or optane - raw engineering numbers are not salesy
Rotonen
2018-06-25 21:21:54
sure. I though it was worth checking out regardless.
Fireduck
2018-06-25 21:38:23

GCP should be able to get up to 40K read IOPS with local SSD...
Protovist
2018-06-25 21:38:24
https://cloud.google.com/compute/docs/disks/performance#ssd-pd-performance
Protovist
2018-06-25 21:40:17
@Rotonen
What kind of computer are you?
Ninja
2018-06-25 21:42:32
@Rotonen is a real boy!
Tyler Boone
2018-06-25 21:43:05
(that's a Pinocchio reference, for those not in the know)
Tyler Boone
2018-06-25 21:48:06
@Ninja hopefully a lockstep mainframe
Rotonen
2018-06-25 21:48:15
I'm a T-1000
Clueless
2018-06-25 21:51:03
There is 1M~2M???
Ninja
2018-06-25 21:52:45
https://www.youtube.com/watch?v=J6d1K7YM7IA YouTube Video: Jonathan Coulton- Todd the T1000
Tyler Boone
2018-06-25 21:52:57
no, a proper mainframe would probably blow past 10M, but no one wants to afford that for snowblossom
Rotonen
2018-06-25 21:53:05

I used to mine on http://snowday.fun pool, but haven't received any share since yesterday. Is there a problem with the pool?
Johannes
2018-06-25 21:53:15
(and yes, I am using field 7)
Johannes
2018-06-25 21:53:20
but any quad channel system should give you ~1M
Rotonen
2018-06-25 21:54:02
@Johannes if the pool has not found a block, no rewards get paid out - people are swapping between pools from time to time for whatever reason
Rotonen
2018-06-25 21:54:11
The equipment is very large
Ninja
2018-06-25 21:54:49
hmk, just wondering as the pool found blocks pretty regularly, and since the diff is down since field.6...
Johannes
2018-06-25 21:55:12
is there any way to see which pool has what hash-rate?
Johannes
2018-06-25 21:55:28
only if the pools disclose that and only if you believe what they report
Rotonen
2018-06-25 21:55:38
i mean it's estimates on estimates and no one prevents anyone from lying
Rotonen
2018-06-25 21:55:47
and bigger hashrates currently draw a crowd
Rotonen
2018-06-25 21:56:01
i'm not suspecting anyone of bumping their numbers, but FYI
Rotonen
2018-06-25 21:56:13
it's pretty obvious from the block explorer which pools have the miners currently
Rotonen
2018-06-25 21:57:35
ok thanks
Johannes